Czy audyt witryny nie działa u Ciebie prawidłowo?
Istnieje wiele czynników, które mogą powodować blokowanie robota indeksującego narzędzia Audyt witryny na stronach, w zależności od konfiguracji i struktury witryny:
- Plik robots.txt blokuje robota indeksującego
- Niektóre obszary witryny są wykluczone z zakresu indeksowania
- Witryna nie znajduje się bezpośrednio online z powodu współdzielonego hostingu
- Rozmiar strony docelowej przekracza 2 MB
- Strony znajdują się za bramą / w obszarze wymagającym zalogowania
- Tag noindex blokuje robota indeksującego
- DNS nie rozpoznaje domeny – domena wprowadzona w konfiguracji znajduje się offline
- Treść witryny oparta na JavaScript – chociaż narzędzie Audyt witryny potrafi renderować kod JS, mimo to może on powodować niektóre problemy
Kroki rozwiązywania problemów
Zanim się skontaktujesz z naszym zespołem wsparcia w celu uzyskania pomocy, wykonaj przedstawione kroki rozwiązywania problemów i sprawdź, czy uda Ci się wprowadzić pewne zmiany samodzielnie.
Plik robots.txt zawiera instrukcje przeznaczone dla botów, które określają, jak należy indeksować strony witryny (lub jak ich nie indeksować). Możesz zezwolić albo zabronić takim botom jak Googlebot lub Semrushbot indeksowania całej Twojej witryny lub jej określonych obszarów, używając takich poleceń jak allow, disallow oraz crawl delay.
Jeśli Twój plik robots.txt zabrania naszemu botowi indeksowania witryny, narzędzie Audyt witryny nie będzie w stanie jej sprawdzić.
Możesz przejrzeć swój plik robots.txt pod kątem ewentualnych poleceń disallow, które uniemożliwiają dostęp do witryny robotom indeksującym takim jak nasz.
Aby zezwolić botowi audytu witryny Semrush (SiteAuditBot) na skanowanie Twojej witryny, dodaj następujące pozycje do pliku robots.txt:
User-agent: SiteAuditBot
Disallow:
(zostaw puste miejsce po „Disallow:”)
Oto przykładowy wygląd pliku robots.txt:

Zwróć uwagę na różne polecenia w zależności od agenta użytkownika (robota indeksującego) wymienionego w pliku.
Jest to plik publiczny i aby został znaleziony, musi być hostowany na najwyższym poziomie witryny. Aby znaleźć plik robots.txt określonej witryny, wprowadź w przeglądarce jej domenę główną, a następnie /robots.txt. Przykładowo plik robots.txt witryny Semrush.com znajduje się pod adresem https://sr02.devserver.cv/robots.txt.
Oto wybrane terminy, które można znaleźć w pliku robots.txt:
- User-Agent = internetowy robot indeksujący, dla którego są przeznaczone instrukcje.
- Przykład: SiteAuditBot, Googlebot
- Allow = polecenie (tylko w przypadku Googlebota), które informuje bota, że może zindeksować określoną stronę lub określony obszar witryny, nawet jeśli strona lub folder nadrzędny są zabronione.
- Disallow = polecenie, które informuje bota, że nie wolno mu indeksować określonego adresu URL lub podfolderu witryny.
- Przykład: Disallow: /admin/
- Crawl Delay = polecenie, które informuje bota, ile sekund ma odczekać przed wczytaniem i zindeksowaniem kolejnej strony.
- Sitemap = wskazuje, gdzie znajduje się plik sitemap.xml odpowiadający określonemu adresowi URL.
- / = użyj symbolu „/” po poleceniu disallow, aby poinformować bota, że ma w ogóle nie indeksować witryny
- * = symbol wieloznaczny reprezentujący dowolny ciąg możliwych znaków w adresie URL; umożliwia wskazanie pewnego obszaru witryny lub wszystkich agentów użytkownika (botów).
- Przykład: Disallow: /blog/* wskazuje wszystkie adresy URL w podfolderze bloga witryny
- Przykład: User-agent: * wskazuje instrukcje przeznaczone dla wszystkich botów
Więcej informacji na temat specyfikacji pliku robots.txt znajdziesz w Google lub na blogu Semrush.
Jeśli na głównej stronie witryny zobaczysz poniższy kod, oznacza to, że nie wolno nam indeksować/śledzić jej linków, a nasz dostęp jest zablokowany.
Ewentualnie strona zawierająca co najmniej jeden z poniższych tagów: „noindex”, „nofollow”, „none” spowoduje błąd indeksowania.
Aby umożliwić naszemu botowi zindeksowanie takiej strony, usuń tagi „noindex” z jej kodu. Aby uzyskać więcej informacji na temat tagu noindex, zapoznaj się z tym artykułem pomocy Google.
Aby dodać bota do białej listy, skontaktuj się z webmasterem lub dostawcą hostingu i poproś o dodanie do białej listy bota pod nazwą SiteAuditBot.
Adresy IP bota: 85.208.98.128/25 (podsieć używana tylko przez narzędzie Audyt witryny)
Bot używa do połączenia standardowych portów HTTP 80 i HTTPS 443.
Jeśli do zarządzania witryną używasz jakichś wtyczek (na przykład Wordpressa) lub sieci CDN, również w nich musisz dodać do białej listy adres IP bota.
Aby dodać bota do białej listy w Wordpressie, skontaktuj się z obsługą Wordpressa.
Do sieci CDN, które najczęściej blokują naszego robota indeksującego, należą:
- Cloudflare – instrukcję dodawania do białej listy znajdziesz tutaj
- Imperva – instrukcję dodawania do białej listy znajdziesz tutaj
- ModSecurity – instrukcję dodawania do białej listy znajdziesz tutaj
- Sucuri – instrukcję dodawania do białej listy znajdziesz tutaj
Uwaga: jeśli korzystasz ze współdzielonego hostingu, istnieje możliwość, że dostawca hostingu nie pozwoli dodać żadnych botów do białej listy ani edytować pliku robots.txt.
Dostawcy hostingu
Poniżej znajduje się lista wybranych najpopularniejszych dostawców hostingu w Internecie oraz instrukcja dodawania bota do białej listy u każdego z nich lub informacja o konieczności skontaktowania się z zespołem wsparcia dostawcy w celu uzyskania pomocy:
- Siteground – instrukcja dodawania do białej listy
- 1&1 IONOS – instrukcja dodawania do białej listy
- Bluehost* – instrukcja dodawania do białej listy
- Hostgator* – instrukcja dodawania do białej listy
- Hostinger – instrukcja dodawania do białej listy
- GoDaddy – instrukcja dodawania do białej listy
- GreenGeeks – instrukcja dodawania do białej listy
- Big Commerce – wymagany kontakt z zespołem wsparcia
- Liquid Web – wymagany kontakt z zespołem wsparcia
- iPage – wymagany kontakt z zespołem wsparcia
- InMotion – wymagany kontakt z zespołem wsparcia
- Glowhost – wymagany kontakt z zespołem wsparcia
- Hosting – wymagany kontakt z zespołem wsparcia
- DreamHost – wymagany kontakt z zespołem wsparcia
* Uwaga: w przypadku dostawców HostGator i Bluehost podane instrukcje działają, jeśli witryna korzysta z serwera VPS lub dedykowanego hostingu.
Jeśli rozmiar strony docelowej lub łączny rozmiar plików JavaScript/CSS przekracza 2 MB, nasze roboty indeksujące nie będą mogły jej zindeksować z powodu technicznych ograniczeń narzędzia.
Aby dowiedzieć się więcej o czynnikach mogących powodować wzrost rozmiaru i sposobie rozwiązania tego problemu, możesz zajrzeć do tego artykułu na naszym blogu.
Aby zobaczyć, jaka część bieżącego budżetu indeksowania została wykorzystana, przejdź do obszaru Profil – Informacje o subskrypcji i poszukaj wartości „Strony do indeksowania” w sekcji „Zestaw narzędzi SEO”.
W zależności od poziomu subskrypcji obowiązuje ograniczenie w postaci określonej liczby stron, które można zindeksować w ciągu miesiąca (miesięczny budżet indeksowania). Jeśli przekroczysz liczbę stron dozwoloną w ramach posiadanej subskrypcji, musisz wykupić dodatkowe limity lub zaczekać do następnego miesiąca, aż obecne limity się odnowią.
Ponadto, jeśli podczas konfiguracji wystąpi komunikat o błędzie „Osiągnięto limit jednocześnie uruchomionych kampanii”, oznacza to, że została osiągnięta maksymalna liczba jednocześnie uruchomionych audytów witryny dozwolona na danym poziomie subskrypcji.
Z każdym poziomem subskrypcji wiąże się inny limit:
- Konto bezpłatne: 1 audyt witryny w danym czasie
- Zestaw narzędzi SEO Pro: do 2 audytów witryny jednocześnie
- Zestaw narzędzi SEO Guru: do 2 audytów witryny jednocześnie
- Zestaw narzędzi SEO Business: do 5 audytów witryny jednocześnie
Jeśli serwer DNS nie rozpoznał domeny, może to oznaczać, że domena wprowadzona podczas konfiguracji jest offline. Zazwyczaj ten problem występuje, gdy użytkownik wprowadzi domenę główną (example.com), nie zdając sobie sprawy, że wersja witryny w postaci domeny głównej nie istnieje i zamiast niej należy wprowadzić wersję WWW witryny (www.example.com).
Aby zapobiec temu problemowi, właściciel witryny może dodać przekierowanie z niezabezpieczonego adresu „example.com” do zabezpieczonego „www.example.com”, który istnieje na serwerze. Ten problem może również wystąpić w odwrotnej sytuacji, gdy domena główna jest zabezpieczona, a wersja WWW nie. W takim przypadku wystarczy przekierować wersję WWW do domeny głównej.
Jeśli strona główna zawiera linki do pozostałych części witryny ukryte w elementach JavaScript, musisz włączyć renderowanie JS, abyśmy mogli je odczytać i zindeksować te strony. Ta funkcja jest dostępna na poziomach Guru i Business subskrypcji zestawu narzędzi SEO.

Aby podczas indeksowania nie zostały pominięte najważniejsze strony witryny, możesz zmienić źródło indeksowania z witryny na mapę witryny. Dzięki temu roboty indeksujące nie pominą żadnych stron, które w sposób naturalny są trudne do znalezienia w witrynie podczas audytu.
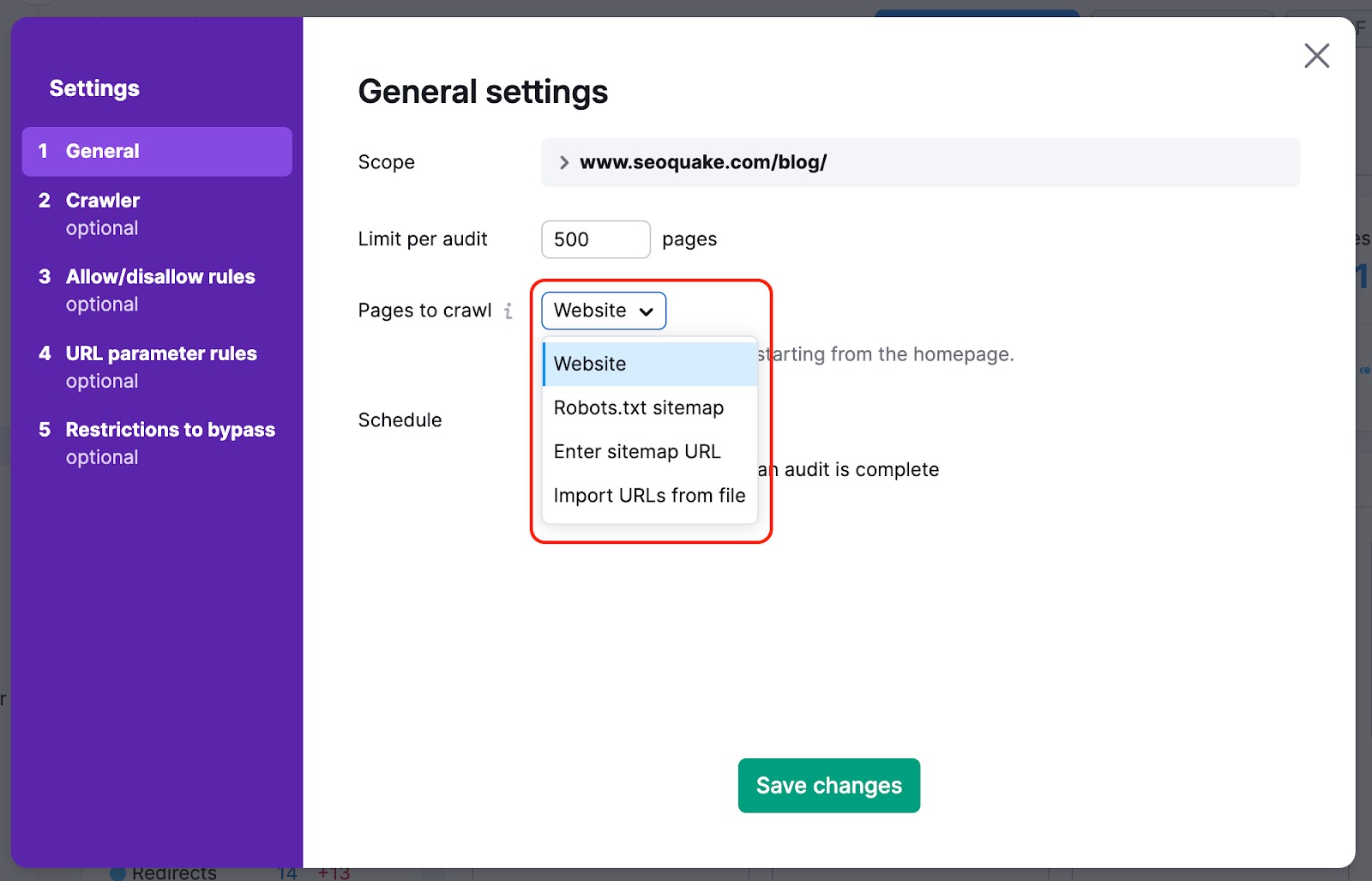
Możemy również przeskanować kod HTML strony z pewnymi elementami JS oraz sprawdzić parametry plików JS i CSS w ramach testów wydajności.
Plik robots.txt witryny może blokować robota indeksującego SemrushBot. Jeśli zmienisz agenta użytkownika z SemrushBot na GoogleBot, witryna prawdopodobnie pozwoli botowi Google na indeksowanie. Aby wprowadzić tę zmianę, znajdź kółko ustawień w projekcie i wybierz pozycję Agent użytkownika.
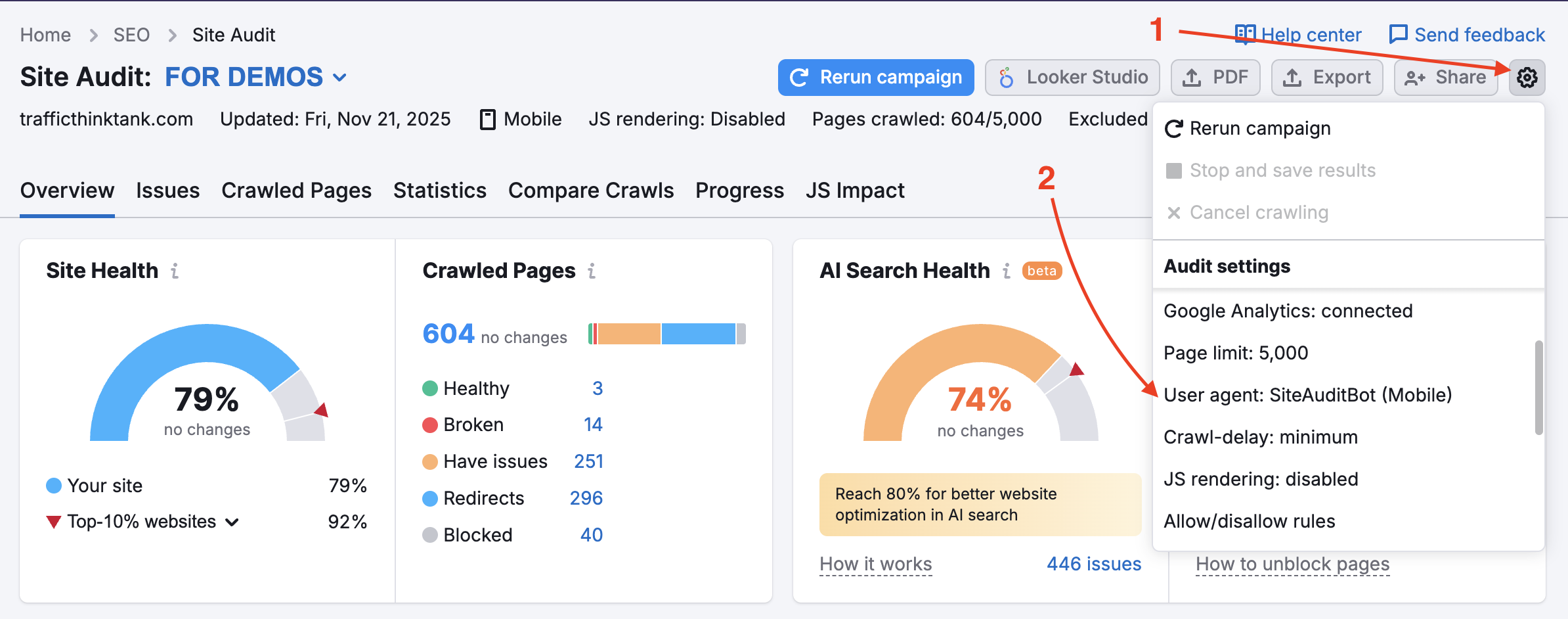
Gdy ta opcja jest włączona, robot indeksujący pominie reguły disallow zawarte w pliku robots.txt, a więc strony i zasoby wewnętrzne, które zwykle są blokowane, mimo to zostaną zindeksowane. Pamiętaj, że skorzystanie z tej opcji wymaga weryfikacji własności witryny.
Ta opcja przydaje się w przypadku witryn przechodzących prace konserwacyjne. Jest też pomocna, kiedy właściciel witryny nie chce modyfikować pliku robots.txt.
Aby audyt objął prywatne obszary witryny, które są chronione hasłem, wprowadź swoje dane logowania w opcji „Indeksuj za pomocą swoich danych logowania” po kliknięciu kółka ustawień.
Stanowczo zaleca się to w przypadku witryn, które wciąż znajdują się w fazie rozwoju lub są prywatne i w pełni chronione hasłem.

Niektóre witryny internetowe i platformy hostingowe, takie jak Shopify, mogą domyślnie blokować nieznane roboty ze względów bezpieczeństwa lub związanych z wydajnością. Jeśli na tych platformach audyt się nie powiedzie, dzięki dodaniu podpisu Web Bot Auth robot indeksujący Semrush będzie mógł się zidentyfikować i udowodnić, że ma autoryzację pozwalającą na dostęp do Twojej witryny.

Jeśli podczas początkowej konfiguracji podpis nie został podany i Twoja witryna zostanie zablokowana, Semrush wykryje to ograniczenie i poprosi o rozwiązanie problemu bezpośrednio z poziomu interfejsu narzędzia.

„Ustawienia robota indeksującego zostały zmienione od czasu poprzedniego audytu. To może wpłynąć na wyniki bieżącego audytu i liczbę wykrytych problemów”.
To powiadomienie pojawia się w narzędziu Audyt witryny po zaktualizowaniu dowolnych ustawień i ponownym uruchomieniu audytu. Nie jest to sygnał problemu, ale raczej uwaga, że jeśli wyniki indeksowania niespodziewanie uległy zmianie, może to być prawdopodobna przyczyna tej sytuacji.
Sprawdź nasz post na blogu Typowe problemy dotyczące SEO i ich rozwiązania.