Bạn có thấy Kiểm tra trang web có gì không ổn không?
Có nhiều lý do khiến các trang có thể chặn bot Kiểm tra trang web dựa trên cấu hình và cấu trúc của trang web của bạn, bao gồm:
- Tệp Robots.txt chặn bot quét
- Phạm vi quét loại trừ một số khu vực của trang
- Trang web không trực tiếp trực tuyến do sử dụng hosting dùng chung
- Dung lượng trang đích vượt quá 2Mb
- Các trang được đặt sau cổng truy cập / đăng nhập
- Bot bị chặn bởi thẻ noindex
- Domain không thể được phân giải bởi DNS – domain bạn nhập trong quá trình thiết lập đang ngoại tuyến
- Nội dung trang web được xây dựng trên JavaScript, dù Kiểm tra trang web có thể kết xuất mã JS, nó vẫn có thể là lý do cho một số vấn đề
Các bước khắc phục sự cố
Thực hiện các bước khắc phục này để xem liệu bạn có thể thực hiện bất kỳ điều chỉnh nào trước khi liên hệ với nhóm hỗ trợ của chúng tôi để được hỗ trợ không.
Tập tin Robots.txt cung cấp hướng dẫn cho bot về việc quét (hoặc không quét) các trang của một trang web. Bạn có thể cho phép và cấm các bot như Googlebot hoặc Semrushbot quét mọi trang của bạn hoặc một số khu vực cụ thể của trang web của bạn bằng cách sử dụng các lệnh như Allow, Disallow, và Crawl Delay.
Nếu robots.txt của bạn đang cấm bot của chúng tôi quét trang web của bạn, công cụ Kiểm tra trang web của chúng tôi sẽ không thể kiểm tra trang của bạn.
Bạn có thể kiểm tra tập tin Robots.txt của mình để xem có lệnh Disallow nào ngăn các bot như của chúng tôi truy cập vào trang web của bạn.
Để cho phép bot Kiểm tra trang web của Semrush (SiteAuditBot) quét trang web của bạn, hãy thêm nội dung sau vào tệp robots.txt của bạn:
User-agent: SiteAuditBot
Disallow:
(có một dấu cách sau “Disallow:”)
Dưới đây là một ví dụ của tập tin robots.txt:

Lưu ý các lệnh khác nhau dựa trên tác nhân người dùng (bot quét) mà tập tin đang hướng tới.
Các tập tin này thuộc dạng công khai và để được tìm thấy, chúng phải được lưu trữ ở cấp cao nhất của một trang web. Để tìm tập tin robots.txt của một trang web, hãy nhập domain gốc của một trang sau đó là /robots.txt vào trình duyệt của bạn. Ví dụ: tập tin robots.txt trên Semrush.com được tìm thấy tại https://sr02.devserver.cv/robots.txt.
Một số thuật ngữ bạn có thể thấy trên tập tin robots.txt bao gồm:
- User-Agent = bot quét trang web đang nhận hướng dẫn từ bạn.
- Ví dụ: SiteAuditBot, Googlebot
- Allow = lệnh (chỉ dành cho Googlebot) cho biết bot rằng nó có thể quét một trang hoặc khu vực cụ thể của một trang, ngay cả khi trang hoặc thư mục cha bị cấm.
- Disallow = lệnh cho bot không quét một URL hoặc thư mục con cụ thể của một trang web.
- Ví dụ: Disallow: /admin/
- Crawl Delay = lệnh cho các bot biết số giây cần chờ trước khi tải và quét một trang khác.
- Sitemap = chỉ ra vị trí tập tin sitemap.xml cho một URL cụ thể.
- / = sử dụng ký hiệu “/” sau lệnh cấm để chỉ dẫn bot không quét toàn bộ trang web của bạn
- * = một ký hiệu đại diện (wildcard) cho bất kỳ chuỗi ký tự nào có thể có trong một URL, được sử dụng để chỉ một khu vực của một trang web hoặc tất cả các tác nhân người dùng.
- Ví dụ: Disallow: /blog/* sẽ chỉ ra tất cả các URL trong thư mục con blog của một trang web
- Ví dụ: User-agent: * sẽ chỉ ra hướng dẫn cho tất cả các bot
Đọc thêm về Thông số của Robots.txt từ Google hoặc trên blog của Semrush.
Nếu bạn thấy đoạn mã sau trên trang chính của một trang web, điều đó cho biết rằng chúng tôi không được phép lập chỉ mục / theo dõi liên kết trên đó, và quyền truy cập của chúng tôi bị chặn.
Hoặc, một trang chứa ít nhất một trong các thẻ sau: "noindex", "nofollow", "none", sẽ dẫn đến lỗi quét.
Để cho phép bot của chúng tôi quét một trang như vậy, hãy loại bỏ các thẻ “noindex” này khỏi mã của trang. Để biết thêm thông tin về thẻ noindex, vui lòng tham khảo bài viết trong Google Trợ giúp.
Để thêm bot vào danh sách cho phép, hãy liên hệ với quản trị viên web hoặc nhà cung cấp dịch vụ lưu trữ và yêu cầu họ thêm SiteAuditBot vào danh sách cho phép.
Các địa chỉ IP của bot là: 85.208.98.128/25 (một subnet chỉ được sử dụng cho Kiểm tra trang web)
Bot đang sử dụng các cổng chuẩn 80 HTTP và 443 HTTPS để kết nối.
Nếu bạn sử dụng bất kỳ plugin nào (ví dụ: Wordpress) hoặc CDN (mạng lưới phân phối nội dung) để quản lý trang web của mình, bạn cũng cần thêm địa chỉ IP của bot vào danh sách cho phép ở trong đó.
Để thêm vào danh sách cho phép trên Wordpress, hãy liên hệ với bộ phận hỗ trợ của Wordpress.
Các CDN phổ biến chặn bot của chúng tôi bao gồm:
- Cloudflare - đọc cách thêm vào danh sách cho phép tại đây
- Imperva - đọc cách thêm vào danh sách cho phép tại đây
- ModSecurity - đọc cách thêm vào danh sách cho phép tại đây
- Sucuri - đọc cách thêm vào danh sách cho phép tại đây
Vui lòng lưu ý: Nếu bạn có dịch vụ lưu trữ chia sẻ, có thể nhà cung cấp dịch vụ lưu trữ của bạn không cho phép bạn thêm vào danh sách cho phép bất kỳ bot nào hoặc chỉnh sửa tập tin Robots.txt.
Nhà cung cấp dịch vụ lưu trữ
Dưới đây là danh sách một số nhà cung cấp dịch vụ lưu trữ phổ biến nhất trên mạng và cách thêm vào danh sách cho phép một bot trên từng nhà cung cấp hoặc liên hệ với đội ngũ hỗ trợ của họ để được trợ giúp:
- Siteground - hướng dẫn thêm vào danh sách cho phép
- 1&1 IONOS - hướng dẫn thêm vào danh sách cho phép
- Bluehost* - hướng dẫn thêm vào danh sách cho phép
- Hostgator* - hướng dẫn thêm vào danh sách cho phép
- Hostinger - hướng dẫn thêm vào danh sách cho phép
- GoDaddy - hướng dẫn thêm vào danh sách cho phép
- GreenGeeks - hướng dẫn thêm vào danh sách cho phép
- Big Commerce - Phải liên hệ với bộ phận hỗ trợ
- Liquid Web - Phải liên hệ với bộ phận hỗ trợ
- iPage - Phải liên hệ với bộ phận hỗ trợ
- InMotion - Phải liên hệ với bộ phận hỗ trợ
- Glowhost - Phải liên hệ với bộ phận hỗ trợ
- Hosting - Bạn phải liên hệ với bộ phận hỗ trợ
- DreamHost - Bạn phải liên hệ với bộ phận hỗ trợ
* Vui lòng lưu ý: các hướng dẫn này dành cho HostGator và Bluehost nếu bạn có một trang web trên VPS hoặc dịch vụ dạng Dedicated Hosting.
Nếu dung lượng trang đích của bạn hoặc tổng dung lượng của các tập tin JavaScript/CSS vượt quá 2Mb, các bộ thu thập thông tin của chúng tôi sẽ không thể xử lý nó do những hạn chế kỹ thuật của công cụ.
Để tìm hiểu thêm về những gì có thể gây ra sự gia tăng dung lượng và cách giải quyết vấn đề này, bạn có thể tham khảo bài viết này từ blog của chúng tôi.
Để xem giới hạn cho việc quét hiện tại của bạn đã được sử dụng là bao nhiêu, hãy truy cập Hồ sơ > Thông tin gói đăng ký và tìm “Trang cần quét” ở mục “Bộ công cụ SEO”.
Tùy vào cấp của gói đăng ký, sẽ có giới hạn số lượng trang có thể quét mỗi tháng (giới hạn quét mỗi tháng). Nếu bạn vượt quá số lượng trang cho phép trong gói đăng ký của mình, bạn sẽ phải mua thêm giới hạn hoặc chờ đến tháng sau khi giới hạn của bạn được làm mới.
Ngoài ra, nếu bạn gặp thông báo lỗi "Bạn đã đạt giới hạn cho các chiến dịch chạy đồng thời" trong quá trình thiết lập, điều đó có nghĩa là bạn đã đạt tối đa số lượt chạy kiểm tra trang web cho phép chạy cùng lúc đối với cấp độ gói đăng ký của bạn.
Mỗi cấp độ gói đăng ký bao gồm các giới hạn khác nhau:
- Tài khoản miễn phí: 1 lượt chạy kiểm tra trang web tại một thời điểm
- Gói công cụ SEO Pro: Tối đa 2 lượt chạy kiểm tra trang web đồng thời
- Gói công cụ SEO Guru: Tối đa 2 lượt chạy kiểm tra trang web đồng thời
- Gói công cụ SEO Business: Tối đa 5 lượt chạy kiểm tra trang web đồng thời
Nếu domain không thể được phân giải bởi DNS, có thể domain bạn đã nhập trong quá trình cấu hình đang ngoại tuyến. Thường thì người dùng gặp vấn đề này khi nhập một domain gốc (ví dụ: example.com) mà không nhận ra rằng phiên bản domain gốc của họ không tồn tại và cần nhập phiên bản WWW của trang web (www.example.com).
Để ngăn xảy ra vấn đề, chủ sở hữu trang web có thể thêm một chuyển hướng từ "example.com" không bảo mật đến "www.example.com" bảo mật đã tồn tại trên máy chủ. Vấn đề này cũng có thể xảy ra theo chiều ngược lại nếu tên domain gốc của một trang đã được bảo mật nhưng phiên bản WWW thì không. Trong trường hợp như vậy, bạn chỉ cần chuyển hướng phiên bản WWW đến domain gốc.
Nếu trang chủ của bạn có liên kết đến phần còn lại của trang web bị ẩn trong các phần tử JavaScript, bạn cần bật kết xuất JS (JS-rendering) để chúng tôi có thể đọc chúng và quét các trang đó. Tính năng này có sẵn trong các cấp gói Guru và Business của Bộ công cụ SEO.

Để không bỏ lỡ các trang quan trọng nhất trên trang web của bạn trong quá trình quét của chúng tôi, bạn có thể thay đổi nguồn quét từ trang web thành sơ đồ trang web, theo cách này, các bot quét sẽ không bỏ lỡ bất kỳ trang nào khó tìm trên trang web trong quá trình kiểm tra.
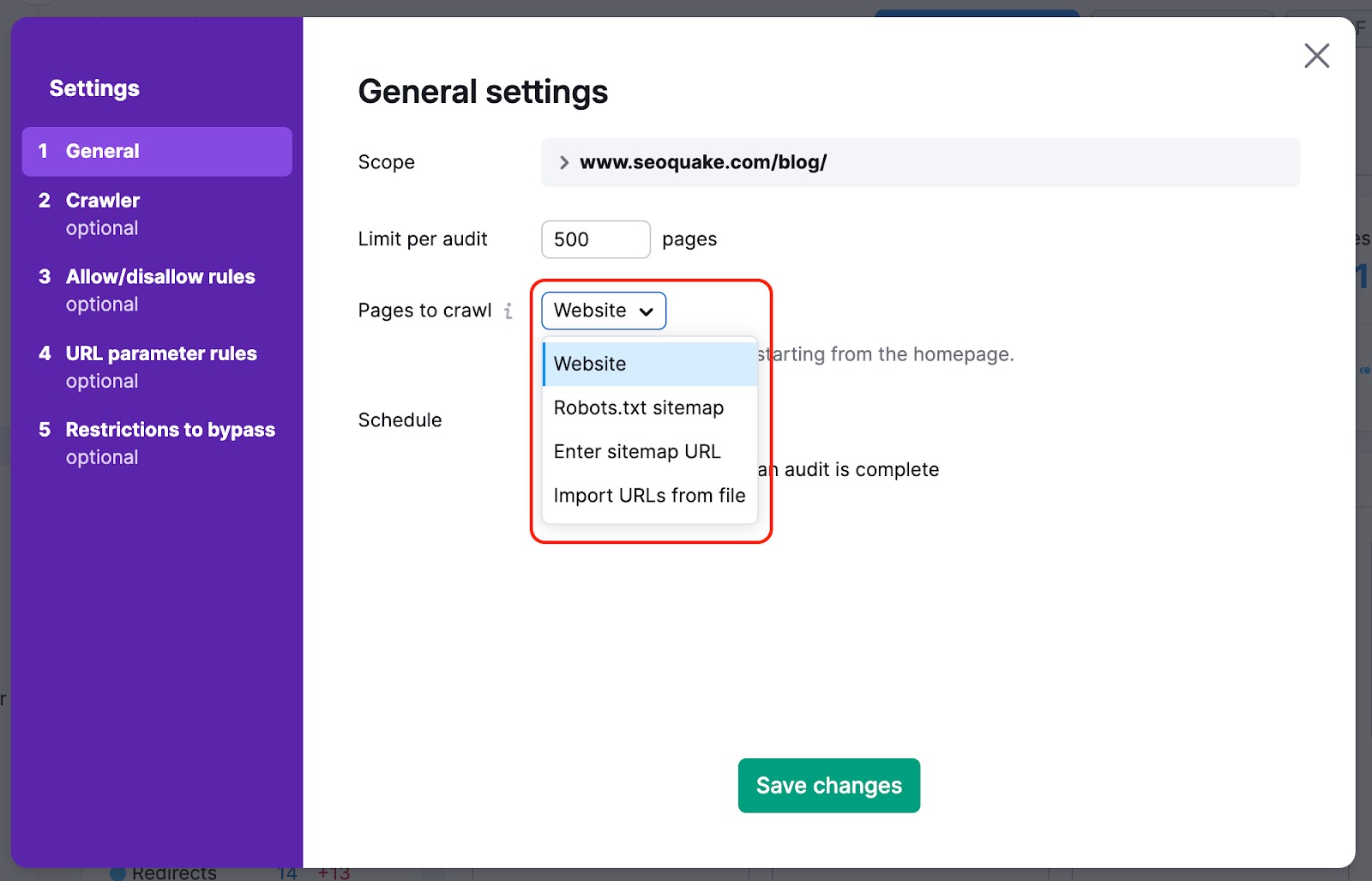
Chúng tôi cũng có thể quét mã HTML của một trang với một số phần tử JS và xem xét các tham số của tập tin JS và CSS của bạn với các bước kiểm tra Hiệu suất của chúng tôi.
Trang web của bạn có thể đang chặn SemrushBot trong tập tin robots.txt. Bạn có thể thay đổi User Agent từ SemrushBot sang GoogleBot, và trang web của bạn có khả năng cho phép User Agent của Google quét. Để thực hiện thay đổi này, tìm biểu tượng cài đặt trong Dự án của bạn và chọn User Agent.
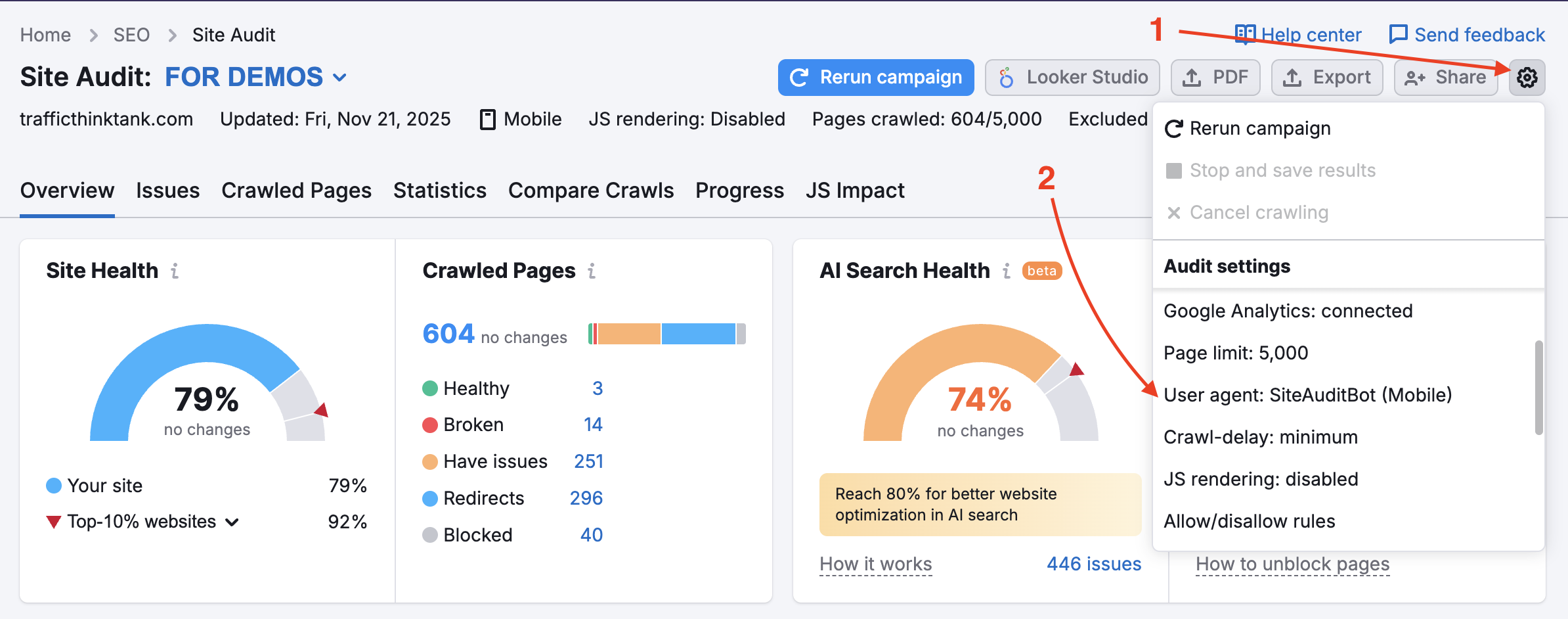
Khi bật tùy chọn này, bot quét sẽ bỏ qua các quy tắc disallow trong robots.txt, vì vậy các trang và tài nguyên nội bộ vốn thường bị chặn vẫn sẽ được quét. Lưu ý, để sử dụng tùy chọn này, bạn cần xác minh quyền sở hữu trang.
Tùy chọn này hữu ích cho các trang web hiện đang được bảo trì. Nó cũng hữu ích khi chủ sở hữu trang không muốn sửa đổi tập tin robots.txt.
Để kiểm tra các khu vực riêng tư được bảo vệ bằng mật khẩu của trang web, hãy nhập thông tin đăng nhập của bạn trong tùy chọn "Quét với thông tin đăng nhập của bạn" dưới biểu tượng cài đặt.
Điều này được khuyến nghị cho các trang đang trong quá trình phát triển hoặc hoàn toàn được bảo vệ bằng mật khẩu.

Một số trang web và nền tảng lưu trữ, như Shopify, có thể mặc định chặn các bot không xác định vì lý do bảo mật hoặc hiệu suất. Nếu quá trình kiểm tra của bạn thất bại trên các nền tảng này, việc thêm chữ ký Web Bot Auth sẽ cho phép bot quét của Semrush tự định danh và chứng minh rằng nó được phép truy cập trang web của bạn.

Nếu bạn không cung cấp chữ ký trong lần thiết lập ban đầu và trang web của bạn bị chặn, Semrush sẽ phát hiện hạn chế này và đưa ra câu lệnh để bạn khắc phục trực tiếp ngay trên giao diện của công cụ.

"Cài đặt bot đã thay đổi kể từ lần quét trước đó của bạn. Điều này có thể ảnh hưởng đến kết quả kiểm tra hiện tại của bạn và số lượng vấn đề được phát hiện."
Thông báo này xuất hiện trong Kiểm tra trang web sau khi bạn cập nhật bất kỳ cài đặt nào và chạy lại kiểm tra. Đây không phải là dấu hiệu của một vấn đề mà là một ghi chú rằng nếu các kết quả thu quét thay đổi một cách bất ngờ, đây có thể là nguyên nhân.
Hãy kiểm tra bài viết trên blog của chúng tôi, Các vấn đề SEO phổ biến & Cách khắc phục.